


深度解读 | 开放型商业知识图谱背后的技术原理
发布时间:2020-09-10作者:DataStory
在上一期的文章《急call市场人,AI会取代你还是为你创造价值?》,我们讲到数说故事构建了一个开放型的商业知识图谱框架体系,本篇文章主要聊聊Mamba Search背后的技术原理。
数说故事在过往服务客户的过程中,通过“算法+人工”的方式,逐步搭建了限定领域下固定知识结构的知识图谱。随着数说故事业务版图的扩张,服务的客户类型从快消品(食品饮料、日化美妆、母婴零售等)逐步向耐用消费品和服务类(政企、汽车、家电等)拓展,涉略领域与日俱增。高速发展的阶段下,固定结构的知识图谱在不同商业场景下的应用受到了束缚。
为更好地满足不同行业客户对知识图谱的需求,数说故事大数据中心于去年启动开放型商业知识图谱搭建项目,基于数说故事多年积累的亿万级数据库,构建开放型商业知识图谱和开放性实体属性挖掘系统Mamba Search。将商业场景中的各种知识以一种更加智能的方式呈现,通过不断挖掘将知识索引。

▲ Mamba Search 界面截图
目前业内已有众多学术论文期刊针对知识图谱的发展趋势和技术原理进行研究分析,本篇文章主要将围绕数说故事在开放性知识提取和实体推断上使用的技术手段及以下两大难点展开介绍。
难点突破
⚠ 开发型知识图谱的算法复杂度较高,如何做到无指定对象的开放性三元组抽取?
⚠ 开放型知识图谱提取结果没有经过有效的归类,下游业务难以使用,怎么办?
知识抽取

上图是我们现有的知识图谱数据流程,核心算法在于开放域抽取以及限定域抽取两个部分。基于自然语言处理抽取的知识分成两种明确不同的类别:开放语义的主谓宾关系,以及限定关系类型的基于长依赖的实体关系抽取。
开放域抽取
开放域抽取,基于语义的主谓宾关系,如:“杨幂代言雅诗兰黛”,我们可以抽取出“[杨幂] - [代言] - [雅诗兰黛]”这样的三元组关系。
开放性知识提取,即从文章中提取由主语、谓语和宾语组成的知识,这是构建知识图谱的核心步骤;开放性指的是不限定谓语的类型,理论上可提取出无限种主语和宾语之间的关系。为了适应社交媒体和不同数据源复杂的语言环境,不同于一般的从原文中直接提取三元组(主语、谓语和宾语)的方案,数说故事知识图谱采取了NER+关系二元组的知识提取方案,我们自研了MELSE模型结构(multi entity-oriented labeling stage extraction model),这样比直接提取三元组结构的传统方案能够提升大概7%的召回率。具体可以分为以下步骤:


将要分析的实体作为“下一句”拼接在原文后,输入数说定制的BERT模型层,将输出的embedding分别输入三个不同的线性转换层,分别得到原文的关系二元组,当原文中的关系二元组多于一个时,可通过对应关系标签,获取谓语和宾语之间的对应关系。
限定域抽取
限定域抽取,基于依赖推理的关系抽取:如:“元气森林推出的气泡水,味道清新,不腻,有利于减肥”,我们需要从中抽取多个关系对。数说定义了商业知识图谱相关的50+特殊关系类型,从品牌研究,到产品研发,再到人群分析,我们都设计了特殊的实体关系类型。
“[元气森林] - [口味] - [清新]”
“[元气森林] - [口感] - [不腻]”
“[元气森林] - [功效] - [减肥]”
限定域的抽取,我们采用BERT作为基础,然后改造最后一层等方式,套用相对经典的NER + Relation Extraction的技术进行提取。
实体推断
知识图谱融合阶段有个比较重要的任务——对实体类型进行推断。前述中,我们有两种比较独立方法进行知识图谱的开放域以及限定域抽取,其中开放域抽取的实体,没有实体的类别信息。类别信息在数说故事商业知识图谱中非常重要,所有的下游应用场景,都需要。下面我们着重介绍一下,实体类别推断的方法。
实体类型推断中,我们采用了现在state-of-art的方法,Graph Embedding + Sentence Embedding的方案。
Graph Embedding,目前比较主流的Knowledge Graph Embedding方法为:Translation Model、复数空间类(RotatE)、双曲空间类(RefH[1])。在文献中,我们发现RefH的模型在Embedding维度较小,如200维时效果显著好于其他,但是在更大的空间上只是稍微好一点。经过测试,在我们的场景实体推断的任务中,RefH的模型取得了最好的效果。
Sentence Embedding,当新知识实体类型未知时,我们会将实体相关的知识组合成一个句子,再用句子向量化的方式将其转换成sentence embedding,再通过训练好的分类算法,可推断出实体的类型,下图是其中一个例子
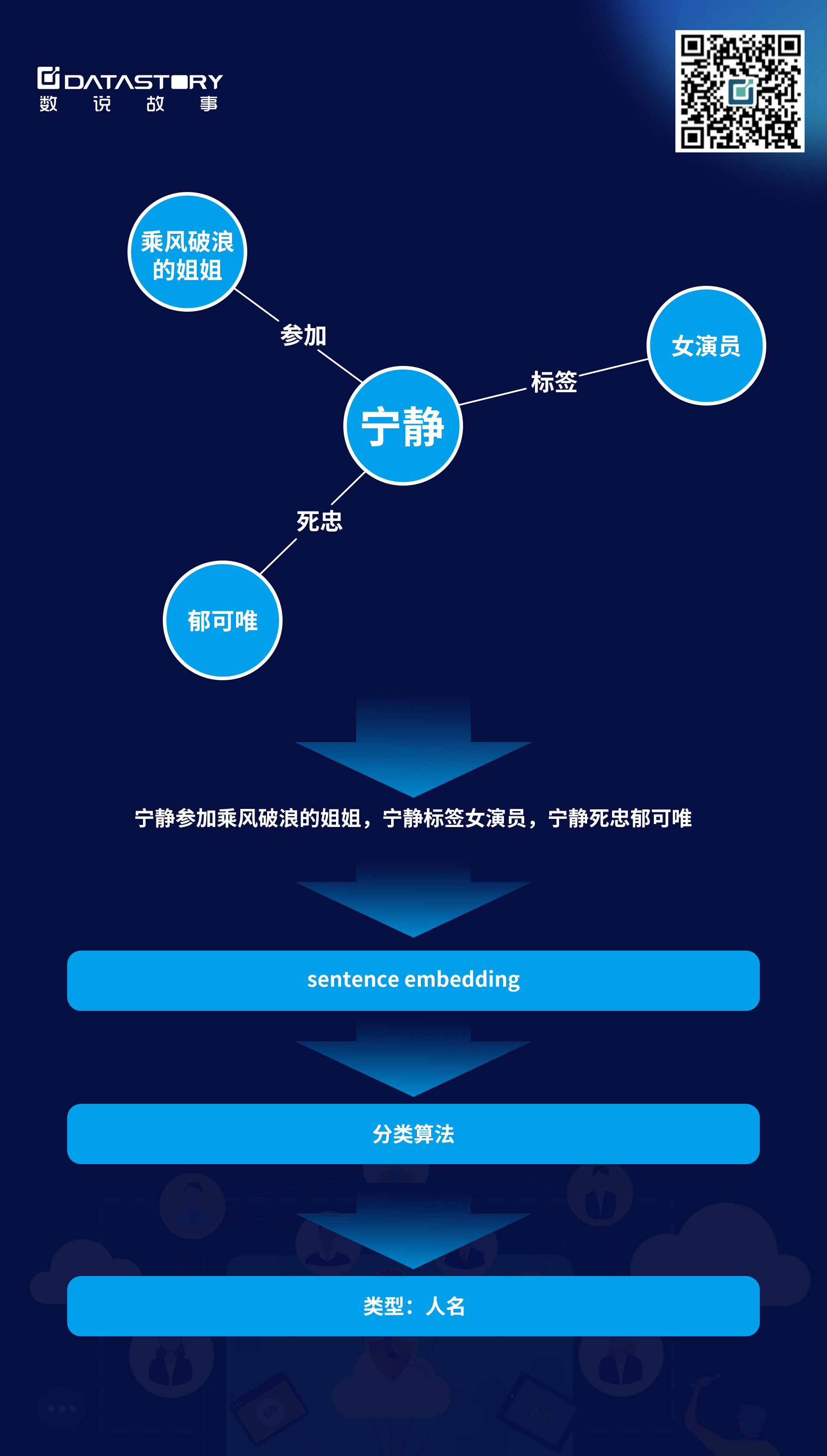
最后我们将实体的Graph Embedding + Sentence Embedding结果拼在一起,传入下游的分类器中,进行实体类型推断。
知识图谱的技术原理覆盖面广泛,包括:如何处理多源实体融合,如何做实体链接与对齐,如何做实体关系预测,如何给实体赋予有意义的重要度等算法模型......
如果您对知识图谱背后的技术原理感兴趣,请持续关注“数说故事”公众号的系列专题介绍,也欢迎在留言区与我们互动交流。
参考文献:
[1] Chami, Ines, et al. "Low-Dimensional Hyperbolic Knowledge Graph Embeddings." Annual Meeting of the Association for Computational Linguistics. 2020.

微信扫描二维码
微博扫描二维码

 Copyright © 2025 广州数说故事信息科技有限公司 All
Rights Reserved 版权所有 备案号:
粤ICP备15073179号
Copyright © 2025 广州数说故事信息科技有限公司 All
Rights Reserved 版权所有 备案号:
粤ICP备15073179号