


IDEA数说故事实验室论文获「国际AI顶会IJCAI-ECAI 2022 Survey Track」收录
发布时间:2022-05-16作者:DataStory
*文章来源| IDEA数字经济研究院
近日,在IDEA研究院主任研究员、IDEA数说故事实验室(IDEA DataStory AI Lab)负责人杨海钦博士的提议和指导下,由来自悉尼大学的两位实习生龙思曲和曹斐祺主要撰写完成的论文“Vision-and-Language Pretrained Models: A Survey”获得IJCAI-ECAI 2022 Survey Track收录。今年IJCAI-ECAI Survey Track共有209篇投稿进入评审阶段,其中38篇文章被收录,录用率仅为18%。


IDEA数说故事实验室借助合作企业数说故事千亿级基础数据平台,提供核心算法,帮助客户实现数字化转型,目前专注于开放域商业事理图谱构建、多模态技术和开放性知识图谱构建。今年初,实验室在杨海钦博士的带领下,充分理解业务需求,研发上线了拥有核心知识产权的事件抽取模块。
此篇论文是对多模态技术的一次探索,后续将在数说故事的更多场景中落地,拓展AI应用的边界。
点击延展阅读:iTalk演讲实录 | 徐亚波博士:我们的目标——冲击商业版AI助手
论文摘要:
预训练模型在计算机视觉(CV)和自然语言处理(NLP)领域已取得巨大成功,随之带动了图文预训练模型(Visual-Language Pretrained Models,VLPMs)的发展。论文综述了图文预训练模型的主要进展,包括主要的模型架构、图文数据的编码方式、基础的预训练和微调技术、图文理解中的主要下游任务,以及未来的主要研究方向。
论文地址:
https://arxiv.org/abs/2204.07356
ReadPaper地址:
https://readpaper.com/paper/675963230332678144
* 推荐通过ReadPaper阅读本文,可一键收藏及浏览参考文献、划线翻译、在线笔记等。
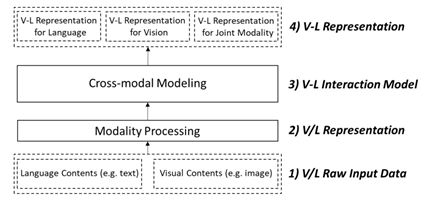
▲图1:图文预训练模型的通用架构
论文开头着重介绍了图文预训练模型的通用架构(参见图1),即图文原始数据输入(V/L Raw Input Data)、图文表征(V/L Representation)、图文交互模型(V-L (Vision-Language) Interaction Model)和图文联合表征 (V-L Representation)。此通用架构适用于大多数现有的图文预训练模型。每个组件、预训练的策略和迁移应用的设计都可以不同。
随后,论文概述了文字数据编码(Language Encoding)和图像数据编码(Vision Encoding)两种不同的图像数据输入方式。文章在回顾现有模型针对图像嵌入方法的创新之余,详细对比了模型在不同细粒度上的嵌入方法,并概括了模型在文字及图像数字编码过程中增强单模态表示的思路、方法和结论。
接着,作者从全新角度,总结出现有的三类图文交互方式模型(V-L interaction models):基于自注意力机制(Self-attention-based)、基于协同注意力机制(Co-attention-based)和基于视觉语义嵌入(Visual-Semantic-Embedding(VSE)-based)的对比学习模型。论文还详尽展示了本领域的预训练数据集,并模块化地总结了各种重要的预训练任务。
最后,论文把视角延伸到两类图文预训练模型的下游任务,即图文理解任务(V-L Understanding)和图文生成任务(V-L Generation),详尽回顾了现有方法在各项下游任务中的验证方式:
● 图文理解任务(V-L Understanding):介绍了视觉问答(Visual Question Answering)、跨模态检索(Cross Modal Retrieval)、文本分类(Text Classification)等图文理解任务,并对现有方法在下游任务上的应用情况进行了回顾(参见表1)。
● 图文生成任务(V-L Generation):介绍了基于多模态或单模态的下游生成式任务,如看图说话(Image Captioning)任务、多模态机器翻译(Multi-modal Machine Translation)任务等。

▲表1:图文理解任务中的下游任务分类
为推进此领域发展,文章最后提出了三个具有前景的研究方向:
● 图文交互建模:
研究如何准确地对齐图像和文本之间在不同细粒度层级上的特征,依旧是一个值得探索的问题。
● 图文预训练策略:
对图文预训练策略的探索,也许可以为视觉语言预训练模型的未来发展提供有价值的指南。
● 训练评估:
找到针对预训练模型的直接评估方法,改善现有训练模型仅依赖下游任务表现,而可能造成的资源计算的浪费。
期待更详细的杂志论文早日付梓,帮助大家更快、更全面了解这一领域的发展。
关于IDEA数说故事实验室
IDEA DataStory AI Lab由数说故事携手IDEA共建,基于数说故事“大数据+AI”丰富的技术栈积累和平台化能力,结合IDEA国际TOP50的超级计算集群优势,将联合国内外顶尖高校和科研院所,围绕AI知识图谱、下一代动态海量事理图谱技术等领域展开国际一流的研究和产业化落地。

杨海钦现任IDEA研究院主任研究员和IDEA数说故事实验室负责人,博士毕业于香港中文大学。杨博士曾任教于香港恒生管理学院,亦曾担任香港中文大学客座副教授,曾就职于美图(中国)、平安寿险,负责自然语言处理的研究和落地。他在机器学习、自然语言处理等领域已发表论文60余篇,获得亚太神经网络学会2018年“年青科学家奖”,并多次入选AI2000经典AI(AAAI/IJCAI)全球最具影响力学者榜单。他曾担任ICONIP'20程序委员会主席、AAAI/IJCAI等机器学习顶议的领域主席。

微信扫描二维码
微博扫描二维码

 Copyright © 2024 广州数说故事信息科技有限公司 All
Rights Reserved 版权所有 备案号:
粤ICP备15073179号
Copyright © 2024 广州数说故事信息科技有限公司 All
Rights Reserved 版权所有 备案号:
粤ICP备15073179号