


澳门大学×数说故事通用人工智能联合实验室论文被AAAI 2025录用
发布时间:2025-03-04作者:DataStory

在数字化浪潮中,品牌生意增长离不开社媒及电商数据洞察,它像精准导航,预知市场机遇,捕捉竞对动态,瞄准增长方向指引品牌优化产品、营销、运营等。但实际应用中,常面临两大痛点:一是海量未标注数据难以利用——例如品牌需分析全网用户对“抗初老”产品的讨论,人工标注的成本高昂,而未标注数据难以直接用于模型训练;二是跨平台数据孤岛——电商、社交、短视频平台数据无法直接互通,导致用户画像片面、分析结果的准确性大打折扣。
近日,澳门大学×数说故事通用人工智能联合实验室最新研究《Progressive Distribution Matching for Federated Semi-Supervised Learning》,提了出渐进分布匹配联邦学习框架FedPDM(Federated Learning with Progressive Distribution Matching),通过约束伪标签分布逐步逼近真实类别先验分布来缓解数据异构性的影响,为解决这一难题提供了突破性的思路和方法。同时,此研究成果成功入选人工智能领域历史最悠久、涵盖内容最广泛的国际顶级学术会议——AAAI 2025。


左右滑动查看更多
(拉到最后【阅读原文】跳转阅读全论文)
01
FedPDM——让AI从“半盲”
到“洞察全局”
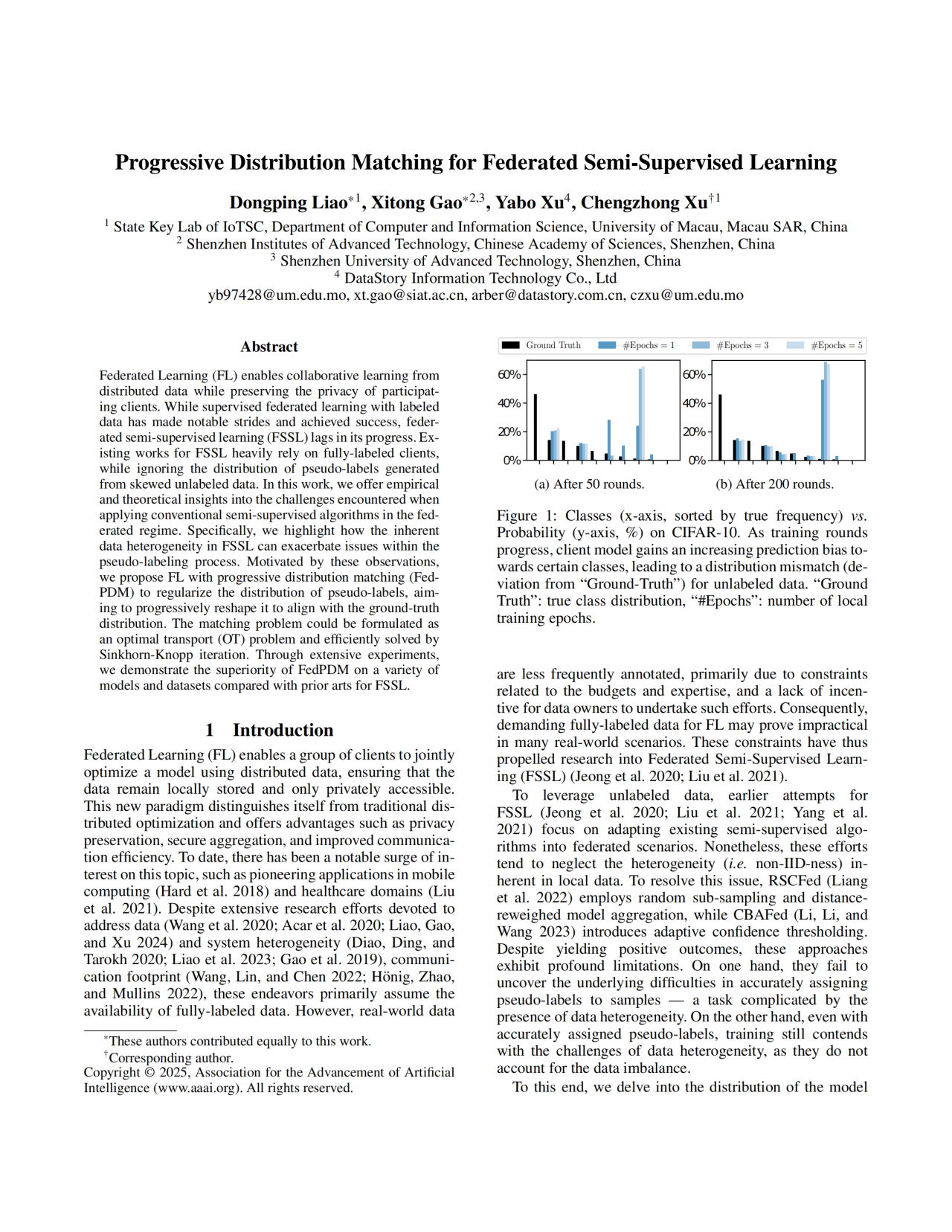
每10亿条社媒数据(涵盖微博、抖音、小红书等平台),仅不足5%的数据带有人工标签,传统分析方法依赖全标注数据训练模型,成本高且无法适应长尾需求(如小众品类分析、品牌个性化定制标签体系)。在联邦半监督学习(FSSL)加持下,虽能利用未标注数据,却因无标签数据中生成的伪标签的分布偏差导致模型“越学越偏”,例如将“敏感肌”需求误判为“油性肌”,从而影响产品研发指引方向。
为降低标注成本、减少模型训练偏差、提高分析准确度,研究团队提出的FedPDM(Federated Learning with Progressive Distribution Matching)方法,其目标是规范伪标签的分布,使其逐渐与真实标签分布对齐,减轻局部数据异质性对训练的影响,最后实现“低标注成本+高精度建模”。
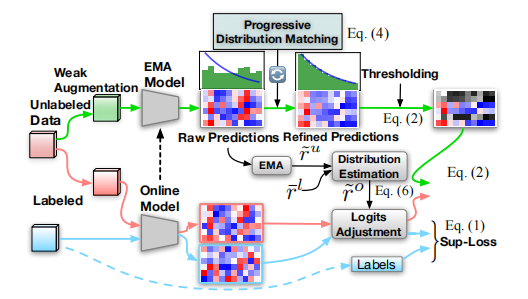
◎FedPDM 在联邦半监督学习(FSSL)客户端上的概述
02
跨越“标注困境”
将“数据荒原”转化为“决策金矿”
实验表明,与其他联邦半监督学习算法相比,FedPDM在多个数据集上展示了更快的收敛速度和更高的准确性,特别是在数据异质性较高的情况下,其优势更为明显。
在混合场景下的 CIFAR-100 数据集上,它比表现最佳的竞争对手高出 4.7%。重要的是,这表明该优势在像 ISIC2018 这样具有更高图像分辨率的大规模数据集上同样适用,从而拓展了其在实际任务中的应用范围。
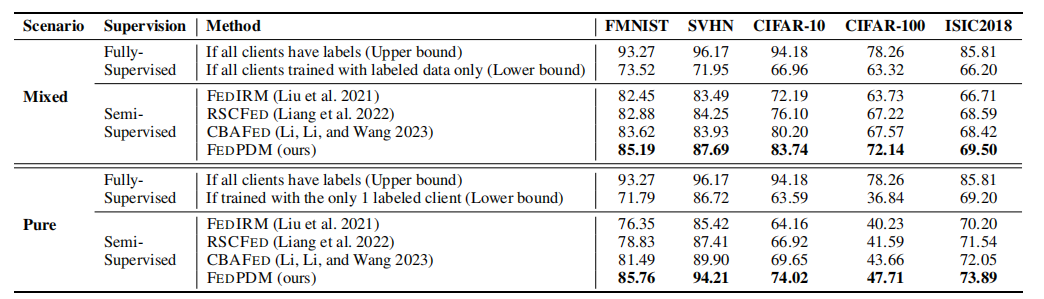
◎混合(Mixed)和纯净(Pure)联邦
半监督学习(FSSL)场景下不同方法性能对比
从混合场景下评估的联邦半监督学习方法的收敛曲线,可以看出,FedPDM 的收敛速度明显快于其竞争对手,得益于分布匹配引入的正则化效果,它的收敛过程也更加稳定和平滑。
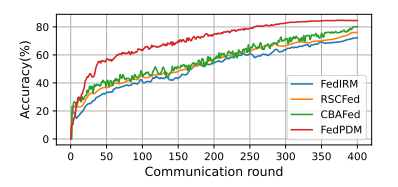
◎CIFAR-10 数据集上联邦
半监督学习(FSSL)方法的收敛曲线对比
本次双方优势互补,以数说故事积累的海量数据和商业应用场景结合澳门大学的学术实力,深度融合理论与实践,有力推动了FedPDM的创新和产业应用,研究成果对提升大数据分析准确度、助力精准商业决策作用显著。
此前,数说故事×澳门大学「通用人工智能联合实验室」合著的《FOCUS: Forging Originality through Contrastive Use in Self-Plagiarism for Language Models》也获国际权威的「ACL 2024」年会收录。
未来,数说故事和澳门大学将继续携手共进,深化在人工智能领域的研究合作,进一步探索大数据、AI、多模态智能及相关技术在更多商业场景中的应用。同时,双方将加强产学研的深度融合,加速科研成果的产业转化,帮助更多企业解决实际商业问题,实现智能商业决策,共同推动行业的创新发展。
About
AAAI 2025.
AAAI Conference on Artificial Intelligence 由国际人工智能促进协会主办,是人工智能领域历史最悠久、涵盖内容最广泛的国际顶级学术会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议,每年举办一届。2025年2月25日,第39届 AAAI 2025 在美国宾夕法尼亚州费城举办,会议为期8天,于3月4日结束。本届AAAI会议共有12957篇有效投稿,录用率为23.4%。


微信扫描二维码
微博扫描二维码

 Copyright © 2025 广州数说故事信息科技有限公司 All
Rights Reserved 版权所有 备案号:
粤ICP备15073179号
Copyright © 2025 广州数说故事信息科技有限公司 All
Rights Reserved 版权所有 备案号:
粤ICP备15073179号